acK: know your pipeline
Toward near-real-time monitoring of pipelines
Craig is a doctoral candidate in Electrical Engineering at the Colorado School of Mines, researching vendor-neutral methods for aligning pipeline inspection data. His work includes an objective minimization algorithm for ILI signal matching, two ILI box matching algorithms (Bayesian and transductive), and an ILI weld matching algorithm that uses odometry error. He holds a Master’s in Computer Science from CSM and a Bachelor’s in Mechanical Engineering from Georgia Tech.
-

Why can’t I use odometry for ILI runcoms?
(15-minute read) Odometry is understood to be useful for sorting inspection features, but it is useless for comparing them. There is too much disagreement. This article presents an alternative to the common “wheel slip” explanation. It describes odometry errors as an unavoidable consequence of bias introduced during navigation by dead reckoning.
-

Vocabulary for pipeline inspection matching (runcoms)
(5 Min Read – Industry) I am a data analyst. I have not seen a set of terminology that is from this perspective. These are the terms I use. Help me improve this? What is confusing?
-

Integrated Cleaning and Inspecting Pig (ICIP): Part 2 – Proximity Sensors (2 of 2)
*(20 Min Read – Technical)* This write-up demonstrates that inexpensive inductive proximity sensors can be used to construct inexpensive inspection tools. Commercial proximity sensors have a proven track record of operating in harsh environmental conditions. They have high shock and vibration resistance. They are chemical resistant and resistant to short circuits. The sensors we used…
-

Integrated Cleaning and Inspecting Pig (ICIP): Part 1 – Mechanical and Electronics (1 of 2)
*(10 Min Read)* This project aims to build an inexpensive screening pig. The use case is that this screening tool will be run frequently, and a composite understanding of the pipe wall will emerge by combining multiple assessments. To that end, the pig should be easy to operate and repair. A field hand should be…
-
Calculating small distances between lat/long coordinates using Excel
*(Technical)* The most common GCS distance calculation, the Spherical Law of Cosines (SLoC), gives poor results at short distances. This is an issue when calculating joint lengths using latitude/ longitude pairs. At these short distances, the spherical law of cosines has a precision of only 4.5%. In contrast, the three alternate techniques I compare with…
-
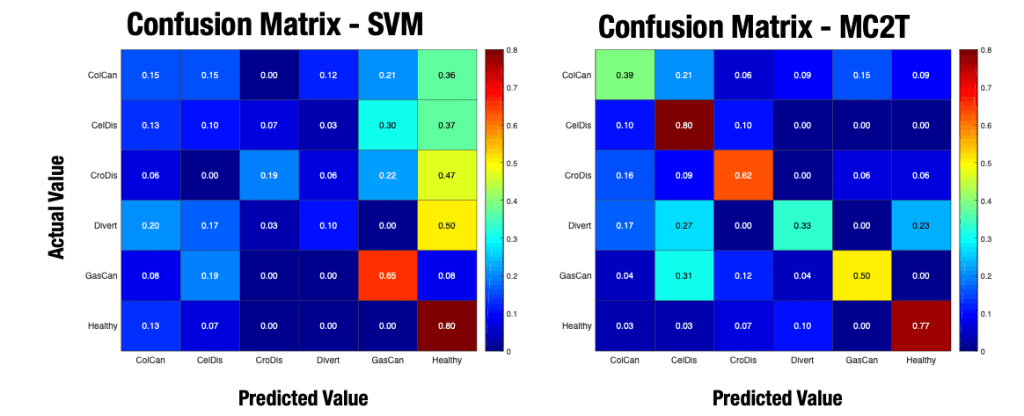
Combining sensing modalities
*(Technical)* Suppose you have had multiple sensors traverse a section of pipe with the intent of detecting axial cracking. Rather than concern ourselves with which tool does the “best” at detecting the phenomenon, we can treat the signal from each inspection as a piece of evidence supporting or refuting the hypothesis that axial cracking is…
-

Why is it called ack?
*(2-minute read)* Short-cycle events like river scouring, tampering, and aggressive corrosion growth can compromise pipeline integrity between inspections and catch an operator unaware. acK for pipelines is a set of tools and practices to address these events using inexpensive, high-temporal-resolution pipeline state monitoring.
-

A game of outliers
*(2-minute read)*Best practices are already pretty good. Best integrity management practices catch almost all cases of impending failures. What we need is a better way of catching outliers.



